Der Fleiss Kappa-Wert berücksichtigt nicht nur die beobachtete Übereinstimmung, sondern auch die zufällig zu erwartende Übereinstimmung.
Es gibt eine rechnerische Verbindung zwischen dem Prozentsatz der richtig erkannten Merkmale (auch bekannt als beobachtete Übereinstimmung oder observed agreement) und dem Fleiss‘ Kappa-Wert. Allerdings ist diese Beziehung nicht linear oder direkt proportional.
Die Formel für Fleiss Kappa lautet:
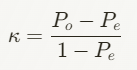
Wobei:
- Po die beobachtete Übereinstimmung ist (der Prozentsatz der richtig erkannten Merkmale)
- Pe die zufällig zu erwartende Übereinstimmung ist
Die Berechnung von Pe hängt von der Verteilung der Bewertungen über die verschiedenen Kategorien ab und ist daher spezifisch für jeden Datensatz.
Wichtige Punkte zur Beziehung zwischen der beobachteten Übereinstimmung und Fleiss‘ Kappa:
- Ein höherer Prozentsatz richtig erkannter Merkmale führt tendenziell zu einem höheren Kappa-Wert, aber nicht immer.
- Selbst bei einer hohen beobachteten Übereinstimmung kann der Kappa-Wert niedrig sein, wenn die zufällig zu erwartende Übereinstimmung ebenfalls hoch ist.
- Der Kappa-Wert kann nie höher sein als die beobachtete Übereinstimmung, da er diese um den Zufallseffekt korrigiert.
- Bei einer perfekten Übereinstimmung (100% richtig erkannte Merkmale) ist der Kappa-Wert 1, unabhängig von der zufällig zu erwartenden Übereinstimmung.
- Bei einer Übereinstimmung, die nicht besser als der Zufall ist, ist der Kappa-Wert 0 oder negativ, unabhängig vom tatsächlichen Prozentsatz der Übereinstimmung.
Berechnung von Pe (zufällig zu erwartende Übereinstimmung)
Die Berechnung von Pe (die zufällig zu erwartende Übereinstimmung) ist ein wichtiger Teil der Kappa-Statistik. Für Fleiss‘ Kappa wird Pe wie folgt berechnet:

Dabei gilt:
- k ist die Anzahl der Kategorien
- pj ist der Anteil aller Bewertungen, die auf die j-te Kategorie entfallen
Um pj zu berechnen, verwenden wir:
Wobei:
- N die Anzahl der zu bewertenden Objekte ist
- n die Anzahl der Bewerter ist
- nij die Anzahl der Bewerter ist, die das i-te Objekt der j-ten Kategorie zugeordnet haben
Hier ist der Prozess Schritt für Schritt:
- Für jede Kategorie j zählen wir, wie oft sie insgesamt über alle Objekte und Bewerter hinweg gewählt wurde.
- Wir teilen diese Summe durch die Gesamtzahl aller Bewertungen (N * n), um pj zu erhalten.
- Wir quadrieren jedes pj.
- Wir summieren alle quadrierten pj -Werte, um Pe zu erhalten.
Diese Methode berücksichtigt die Verteilung der Bewertungen über alle Kategorien, um die Wahrscheinlichkeit einer zufälligen Übereinstimmung zu schätzen.
Ein wichtiger Punkt: Pe repräsentiert die Wahrscheinlichkeit, dass Bewerter zufällig in ihren Bewertungen übereinstimmen, basierend auf der beobachteten Häufigkeit jeder Kategorie.
Beispiel zur Berechnung von Pe
Nehmen wir folgendes Szenario an:
- Wir haben 3 Bewerter (n = 3)
- Es gibt 10 zu bewertende Objekte (N = 10)
- Es gibt 3 Kategorien (k = 3): A, B und C
Angenommen, wir haben folgende Verteilung der Bewertungen:
- Kategorie A wurde insgesamt 12 Mal gewählt
- Kategorie B wurde insgesamt 14 Mal gewählt
- Kategorie C wurde insgesamt 4 Mal gewählt
Schritt 1: Berechnung von p_j für jede Kategorie
Gesamtzahl der Bewertungen = N * n = 10 * 3 = 30
p_A = 12 / 30 = 0.4
p_B = 14 / 30 ≈ 0.467
p_C = 4 / 30 ≈ 0.133
Schritt 2: Quadrieren der p_j-Werte
p_A^2 = 0.4^2 = 0.16
p_B^2 = 0.467^2 ≈ 0.218
p_C^2 = 0.133^2 ≈ 0.018
Schritt 3: Summieren der quadrierten p_j-Werte, um P_e zu erhalten
Pe = 0.16 + 0.218 + 0.018 = 0.396
Also ist in diesem Beispiel Pe ≈ 0.396.
Interpretation:
Dieser Wert bedeutet, dass bei zufälliger Verteilung der Bewertungen basierend auf den beobachteten Häufigkeiten der Kategorien eine Übereinstimmung von etwa 39.6% zu erwarten wäre.
Dieser Pe – Wert würde dann in die Formel für Fleiss‘ Kappa eingesetzt:
Wobei Po die tatsächlich beobachtete Übereinstimmung ist, die wir aus den Daten berechnen würden.